Support Vector Machines (SVM)
Finds the hyperplane that best separates classes with the maximum margin. Effective in high-dimensional spaces.
Theory & Concept
SVM is a powerful classifier that works by finding the optimal hyperplane (decision boundary) that maximizes the margin between the two classes.
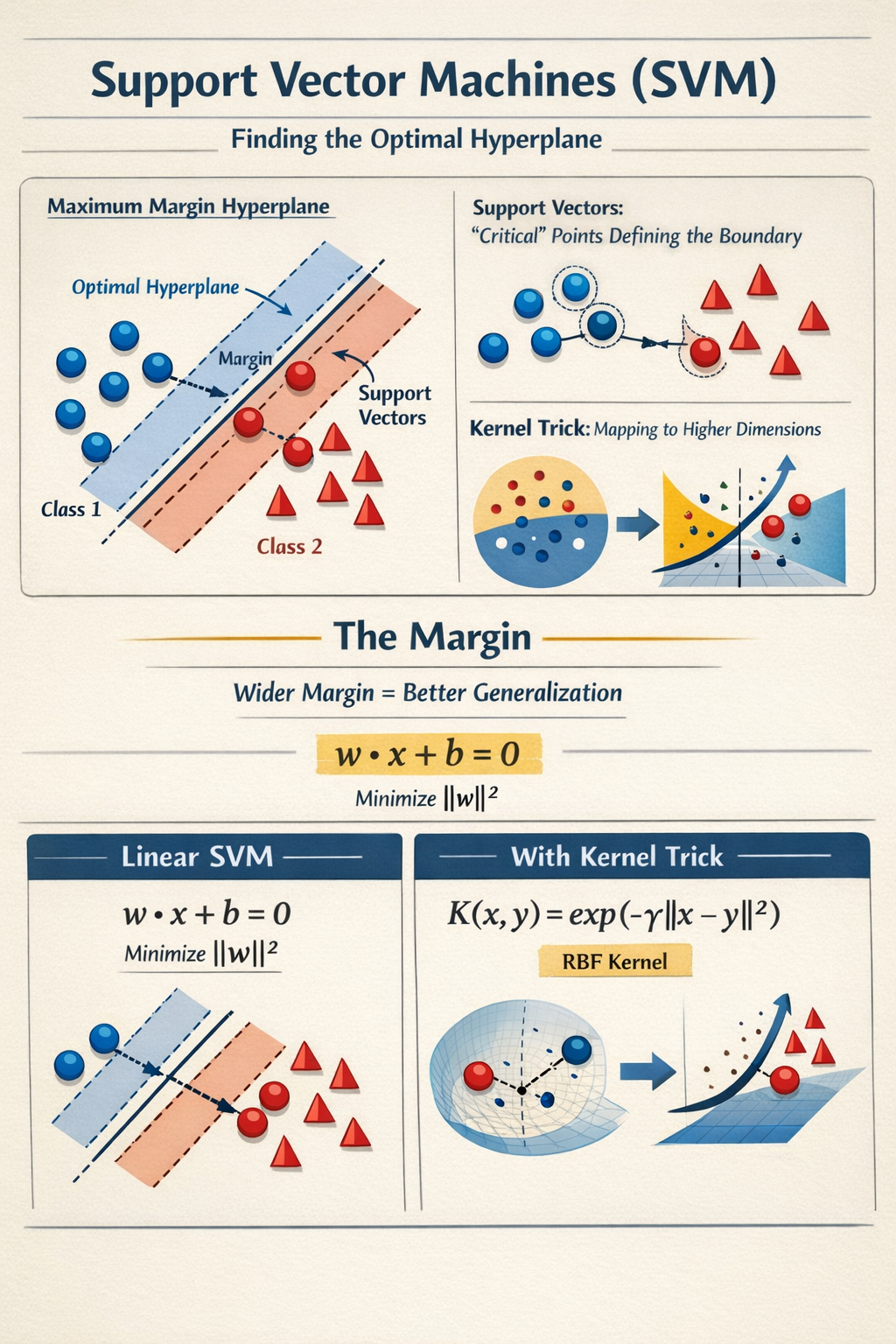
- Support Vectors: The data points closest to the hyperplane. These are the "difficult" points that define the decision boundary.
- Kernel Trick: SVMs can efficiently perform non-linear classification by implicitly mapping inputs into high-dimensional feature spaces.
The Margin
SVM tries to make the "street" separating the classes as wide as possible. A wider margin implies better generalization to unseen data.
Mathematical Intuition
For a linear SVM, we want to multiple and such that:
We minimize subject to constraints (perfect separation).
With the Kernel Trick, we replace the dot product with a kernel function . The most common is the RBF (Radial Basis Function):
This measures similarity between points; points close together influence each other.
Quick Readiness Check
Quick Readiness Check
Is this method a fit for your use case?
Best For
High-dimensional data (e.g., text, genes) where feat > samples. Small to medium datasets.
Prerequisites
Scaling is Mandatory. SVM computes distances; unscaled features will ruin the margin.
Strengths
Robust to overfitting in high dimensions. Effective non-linear classification with kernels.
Weaknesses
Not scalable: Training is O(N^2) or O(N^3). Hard to interpret probability (requires Platt scaling).
Pro Tip
Key parameter trade-off: Bias-Variance with C. High C = Strict (overfit risk). Low C = Smooth (underfit risk).
Code Snippet
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
# 1. Pipeline (Scaling + SVM)
# Always wrap SVM in a pipeline with a Scaler
clf = make_pipeline(StandardScaler(),
SVC(C=1.0, kernel='rbf', gamma='scale', probability=True))
# 2. Train
clf.fit(X_train, y_train)
# 3. Predict
preds = clf.predict(X_test)Parameter Tuning Cheat Sheet
| Parameter | Options / Range | Effect & Best Practice |
|---|---|---|
| C | 0.1 - 1000 | Regularization. High C: Strict margin (risk of overfitting). Low C: Soft margin (smoother boundary). |
| kernel | linear, rbf, poly | Start with rbf (default). Use linear for text decoding or very high dimensions. |
| gamma | scale, 0.001 - 10 | Defines influence of a single point. High gamma: Close points only (complex islands). Low gamma: Far points (smooth). |